
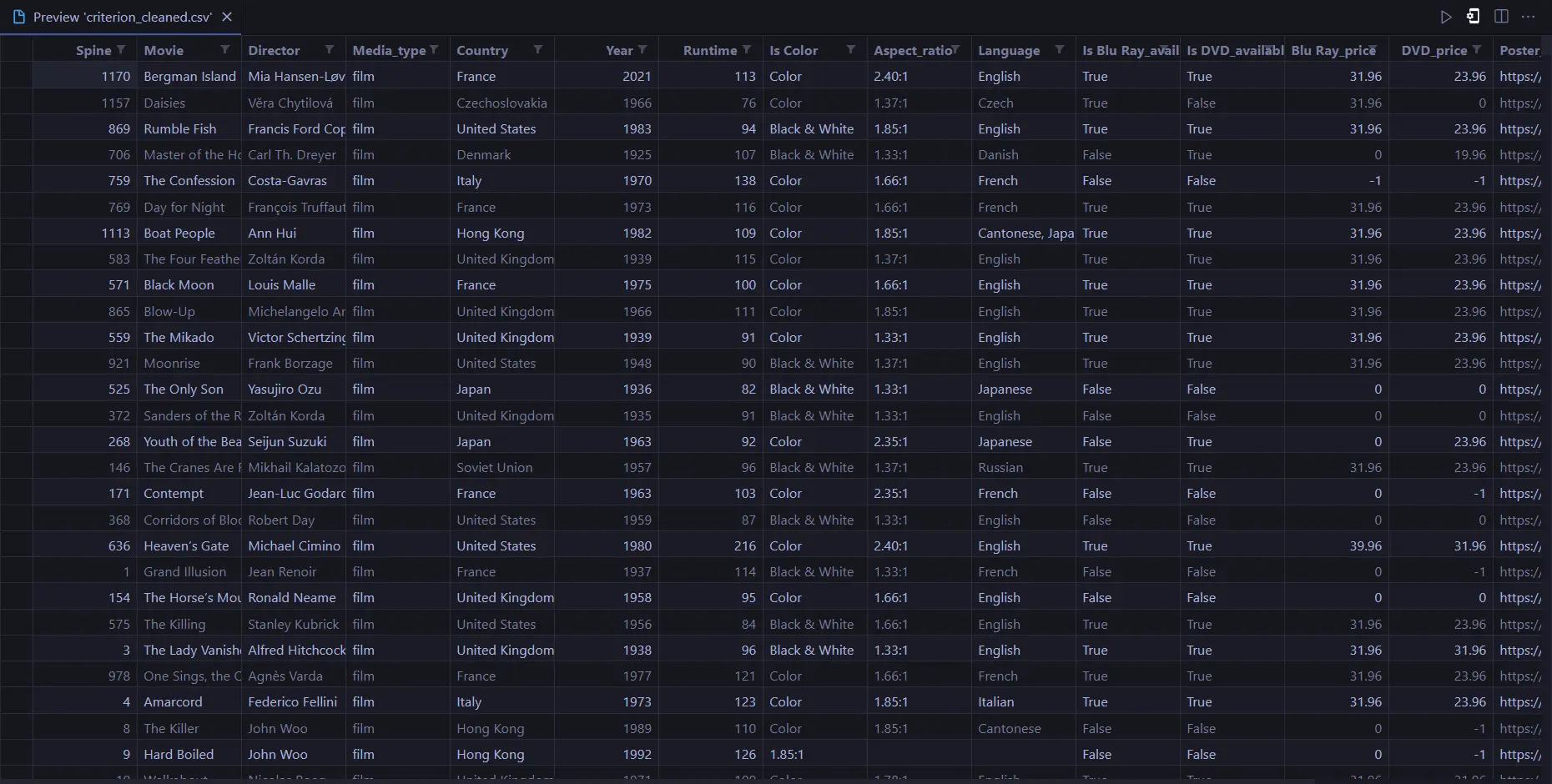
The problem statement revolves around the need for a web scraper designed to extract detailed information about movies from the Criterion Collection. The scraper is tasked with collecting various attributes such as movie title, director, media type, country, year, runtime, aspect ratio, language, Blu-ray and DVD availability, prices, poster URL, page URL, and thumbnail URL. The ultimate goal is to facilitate easy and programmable access to this movie data, catering to both developers and movie enthusiasts.
GITHUB : https://github.com/HighnessAtharva/Criterion-Collection/
Learnings
Building this web scraper involves navigating through the Criterion Film Collection page, utilizing XPath to locate essential data points, and simulating clicks on individual film pages to gather more detailed information. The extraction process includes cleaning the acquired data to maintain a uniform format. The scraper then serially compiles this information and stores it in an Excel Workbook for easy reference.
Pipeline Overview
-
Visit Criterion Film Collection Page: Start by navigating to the listing page (https://www.criterion.com/shop/browse/list) of the Criterion Film Collection.
-
XPath Extraction: Locate the XPath of key data items on the page, which will serve as identifiers for scraping.
-
Simulate Clicks: Simulate clicks on each film page to access more detailed information about the movies.
-
Data Fields Extraction: Extract relevant fields such as movie title, director, media type, country, year, runtime, aspect ratio, language, Blu-ray and DVD availability, prices, poster URL, page URL, and thumbnail URL.
-
Data Cleaning: Ensure the extracted data is in a uniform and clean format for further processing.
-
Excel Workbook: Serially add the collected movie information to an Excel Workbook, providing an organized structure for easy storage and retrieval.
Future Enhancements
Looking ahead, the scraped data can be leveraged to create an API, offering a seamless way for developers and movie enthusiasts to access and interact with the Criterion Collection movie details programmatically.
This web scraper simplifies the process of gathering extensive movie information, making it a valuable tool for those who wish to explore and utilize Criterion Collection data effortlessly.
