
Like Machine Learning with Python? Try Sales Data Analysis Walkthrough
Winning a hackathon is an incredible feeling, and it’s even more special when it’s your very first one. The adrenaline rush of competing against some of the brightest minds in the industry, the satisfaction of solving complex problems, and the thrill of being recognized for your hard work are all emotions that are hard to put into words. In this article, I’ll walk you through the journey of our team who recently won their first ever hackathon, the CRIF Hackathon 2023. From the initial idea to the final presentation, we’ll explore the ups and downs of the experience, and the valuable lessons that were learned along the way. So join us as we relive the excitement of a hackathon victory, and learn what it takes to come out on top.
Want to jump right into the code? Check out the GitHub repo.
Problem Statement
We were give five problem statements to choose from. The first one was to build a framework/utility that takes a company name as an input. The utility should search all the media articles about the input company and present any reputational threatening data on a concise dashboard. With the help of NLP, we were able to build a framework that could scrape news articles from search engines like Google, Yahoo, Duckduckgo and present any reputational threatening data on a concise dashboard.
You can read more about other problem statements here.
Media Analytics
Build a framework/utility that takes a company name as an input. The utility should search all the media articles about the input company and present any reputational threatening data on a concise dashboard.
Following are the functionalities that need to be achieved in order to build a complete solution -
-
Downloader - Download news articles using company name from search engines (Google, Yahoo, Duckduckgo) - Selenium, News API
-
NER module - Named Entity Recognition (Organization + Risk Entity) - Out of the box Spacy NLP models / Taxonomy searches
-
Relationship module - Analyze the articles and carve out sentences(context) where reputation risk elements and company names are present. Can use dependency parsing or predicate classifiers to establish relationships between risk elements and company names
-
Dashboard - Display these relationships in an appropriate Dashboard ⇒ PowerBI / Tableau
Step-by-step guide on how to draw UML Diagrams with ChatGPT
Team
-
Atharva Shah (Yours Truly) - Implementation of the first three modules leveraging NLP, Text Processing, Web Scraping and Debugging. In-charge of leading the team and making the presentation in the final round
-
Gurjas Gandhi - Administration, Management, Insightful Feedback
-
Ali Asger Saifee - Problem-Solving, Curating Word Lists and Generating Tableau Dashboards
-
Aditya Patil - Documentation, Testing and Generating Tableau Dashboards

|
|---|
| The Team (Code Giants) L to R: Gurjas, Aditya, Ali and Atharva |
24-Hour Code Sprint
Since the project heavily relies on Web Scraping, Text Processing, NLP and Data Analysis using Python was an obvious choice for it.
Having prior experience with BeautifulSoup, APIs and Spacy for NLP I immediately got to work and got the first two modules up and running within the first few hours of the hackathon.
NewsAPI - Scraping the latest and relevant news about an organization based on the input query
Regex, BeautifulSoup, Trifulatura - To parse the main content from the webpages and discard irrelevant data. Cleaning up news articles.
Tensorflow - Sentiment Analysis (returning a logit score between 1 to 5)
Spacy - pre-trained roBERta model for improving sentiment analysis and tagging of Named Entity Relationships
Custom Word Stores - to employ a “weighted list” score system based on the word count of negative and offensive words. Three other lists (harassment.txt, countries.txt, lawsuits.txt) were used to tag the articles if repeated words related to it were detected.
Processing CSVs - A lot of file handling was performed. The pipeline consisted of 3 CSVs.
Common.csvthat simply stores the scraped articlesCommon-processed.csvthat performs sentiment analysis on headline and stores the tags, offensive/negative words with the score based on the SpaCy NER moduleCommon-Analysis.csvthat used pandas to join all the fields together and prepare a final CSV for automating the Tableau dashboard.
Spent the most time with this. Most CSVs that made the final
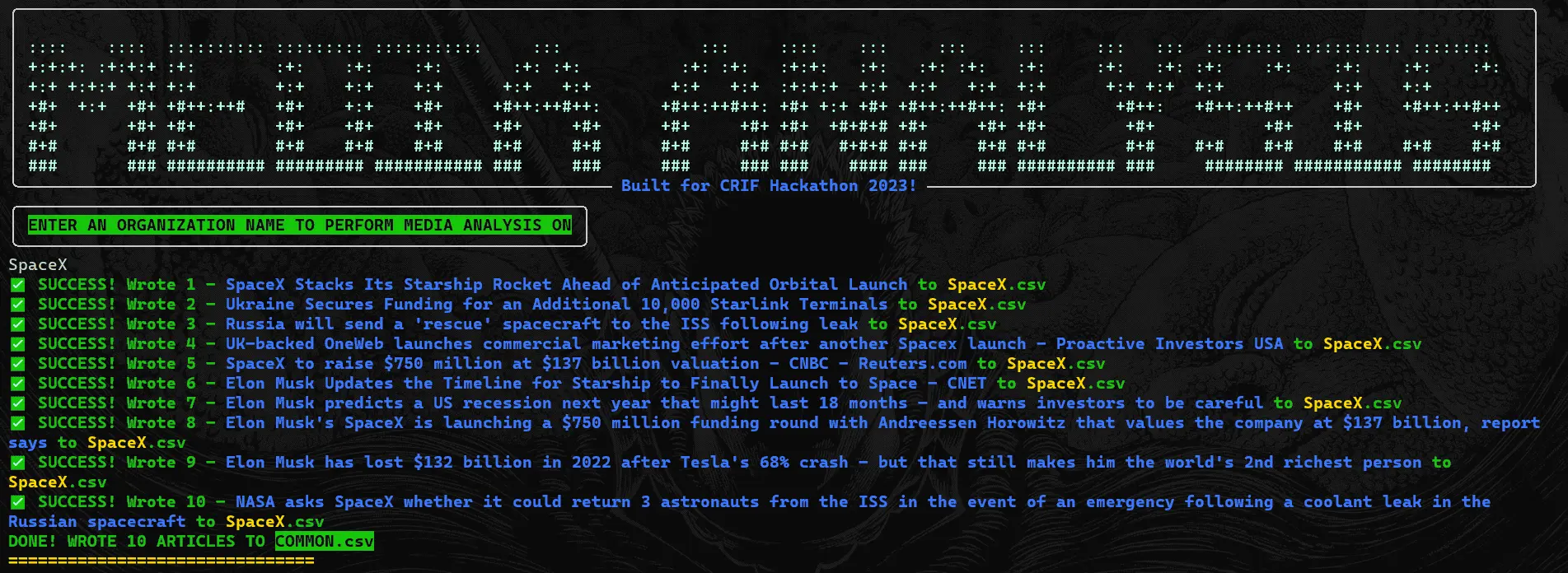
|
|---|
| Custom CLI Tool to Scrape Relevant News Articles based on user input |
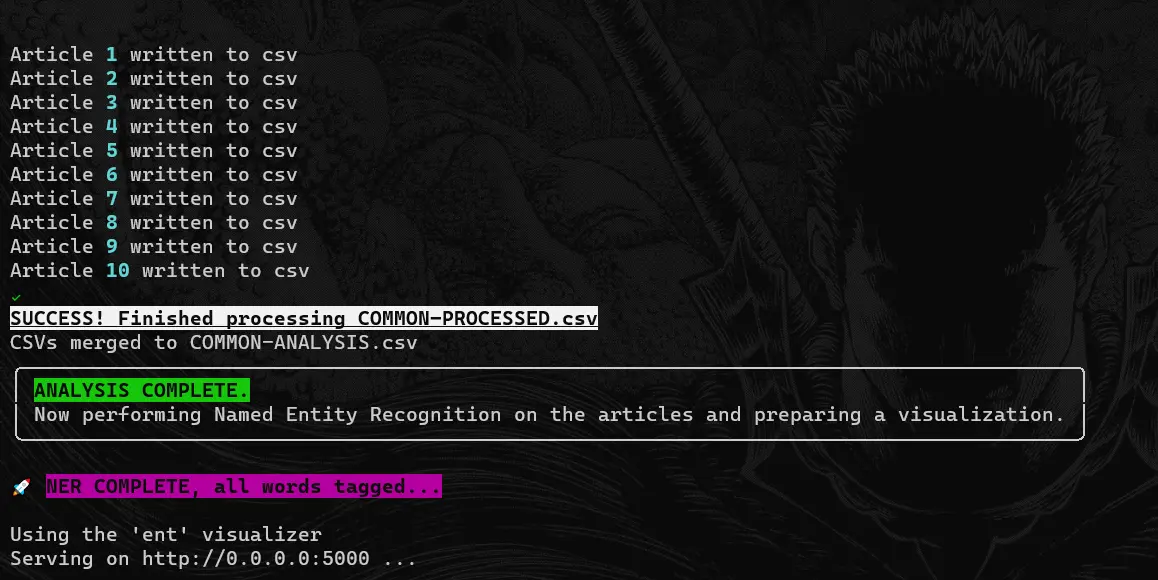
|
|---|
| Sanitization, cleanup and pre-processing with Sentiment Analysis being written to CSV files |

|
|---|
| Named Entity Relationship Mapping with DisplaCy |
Tableau - Taking input of the COMMON-ANALYSIS.csv file, we designed 8 dashboards to present or narrate a story with all our data. Since we had plenty of fields like Article Count, Title,Description, Content (which holds the entire article text), URL, Publisher, Published Date, Headline, Headline Sentiment, Offensive Rating, Negative Words, Offensive Words and Tags it was not much of a hassle. We made good use of several plotting and graphing methods and presented a diverse yet insightful story. Each Tableau report updates after looking up a new organization.
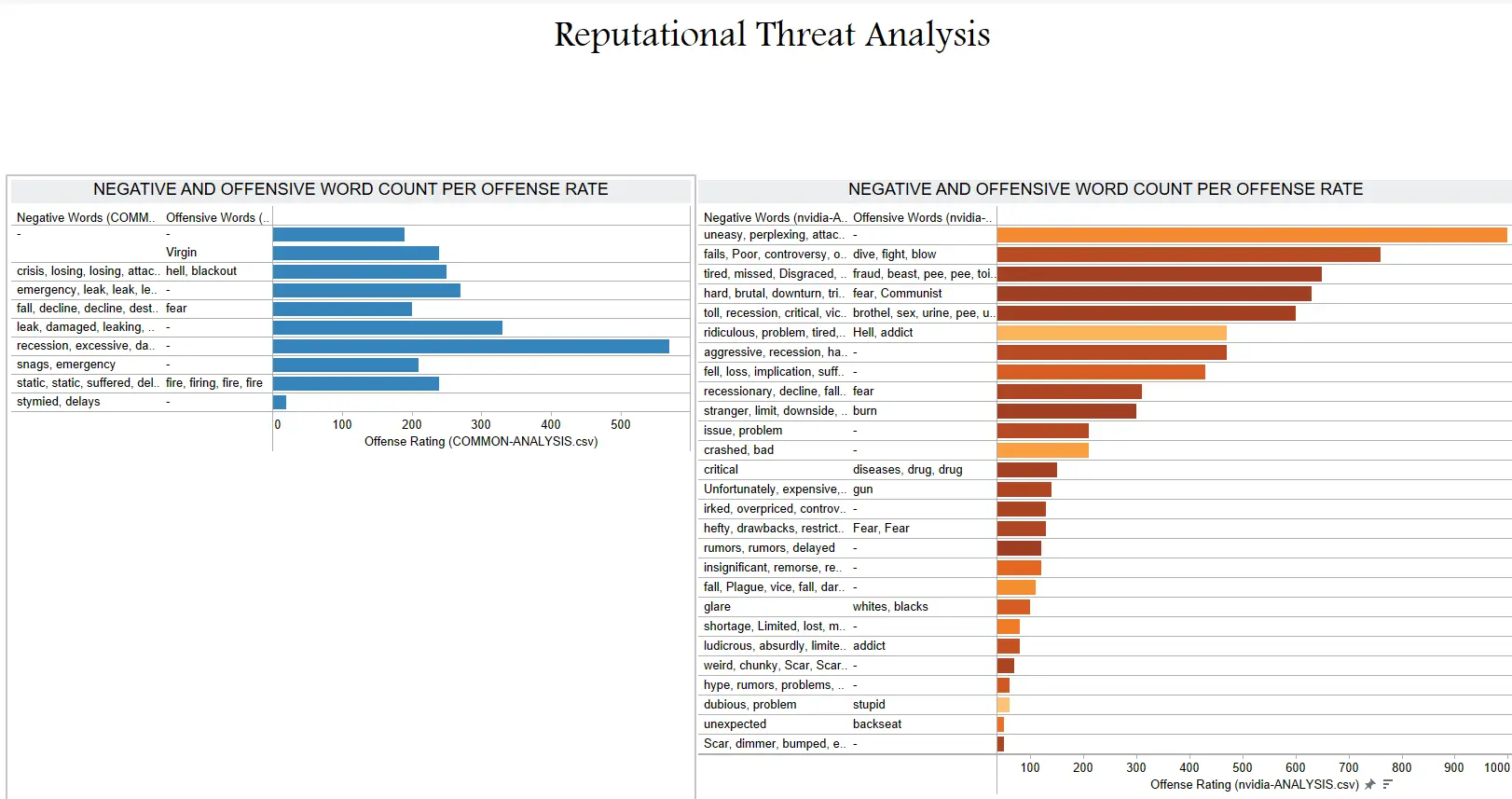
|
|---|
| Tableau Dashboard #1 |
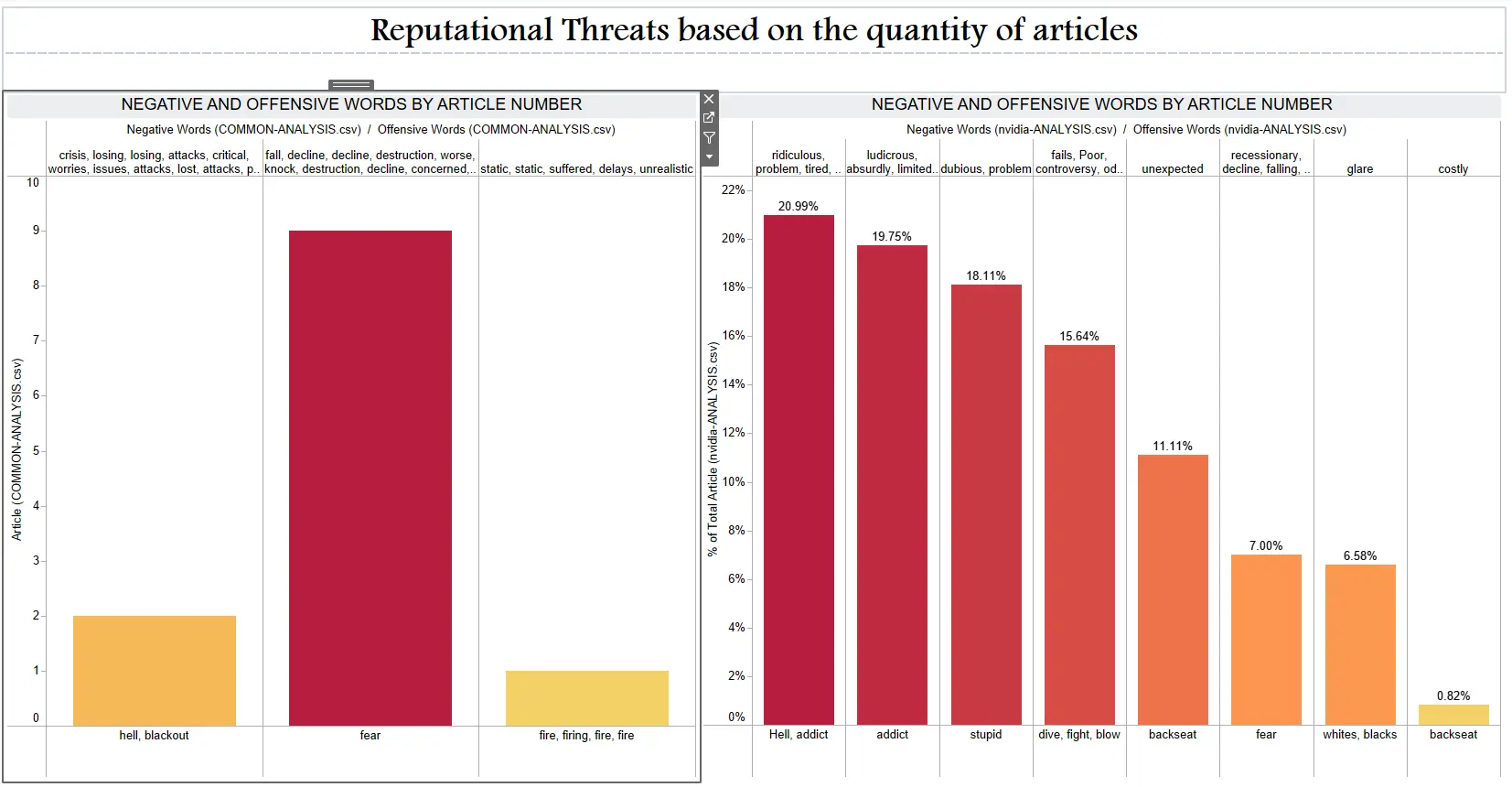
|
|---|
| Tableau Dashboard #2 |
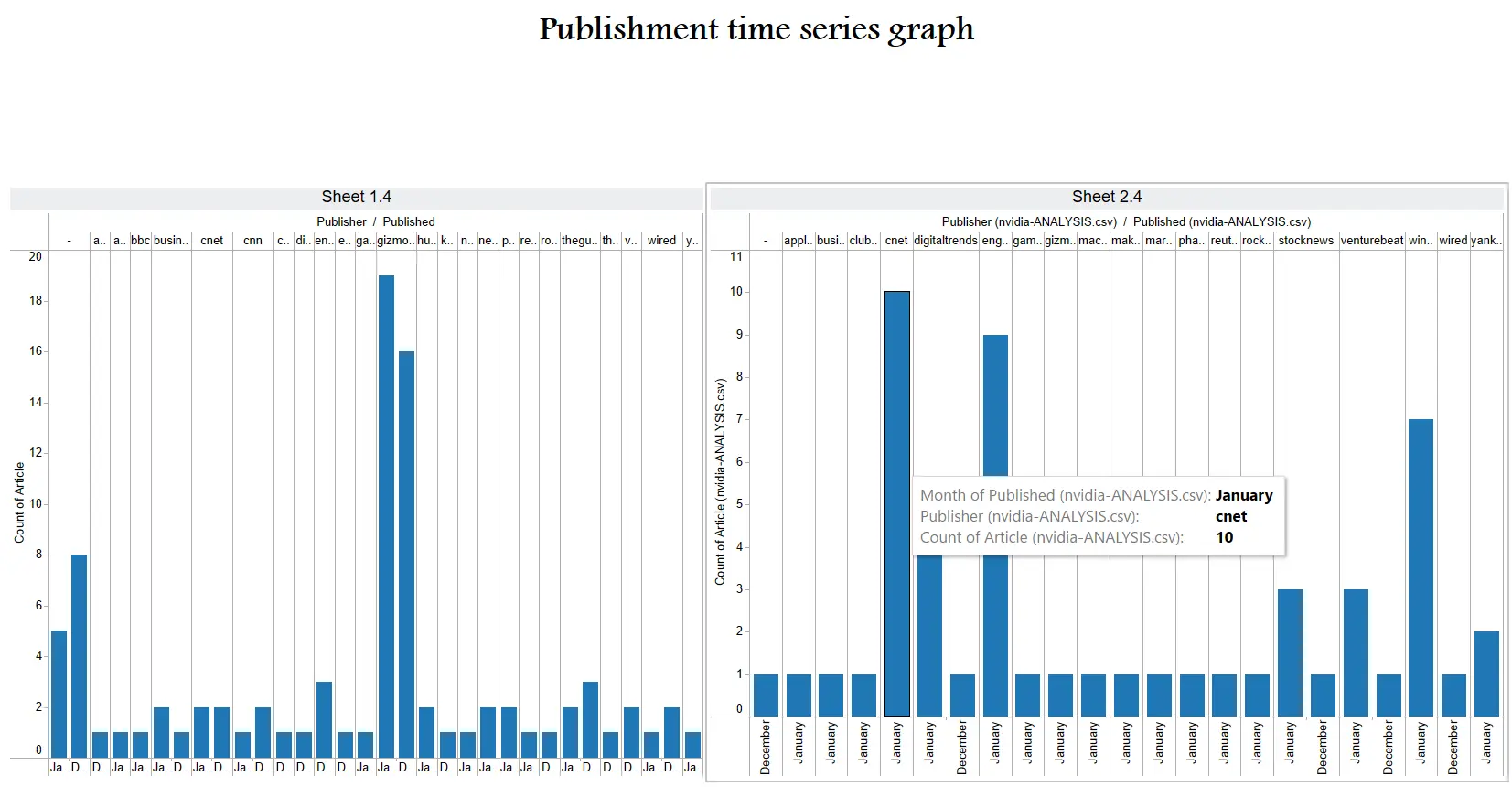
|
|---|
| Tableau Dashboard #3 |
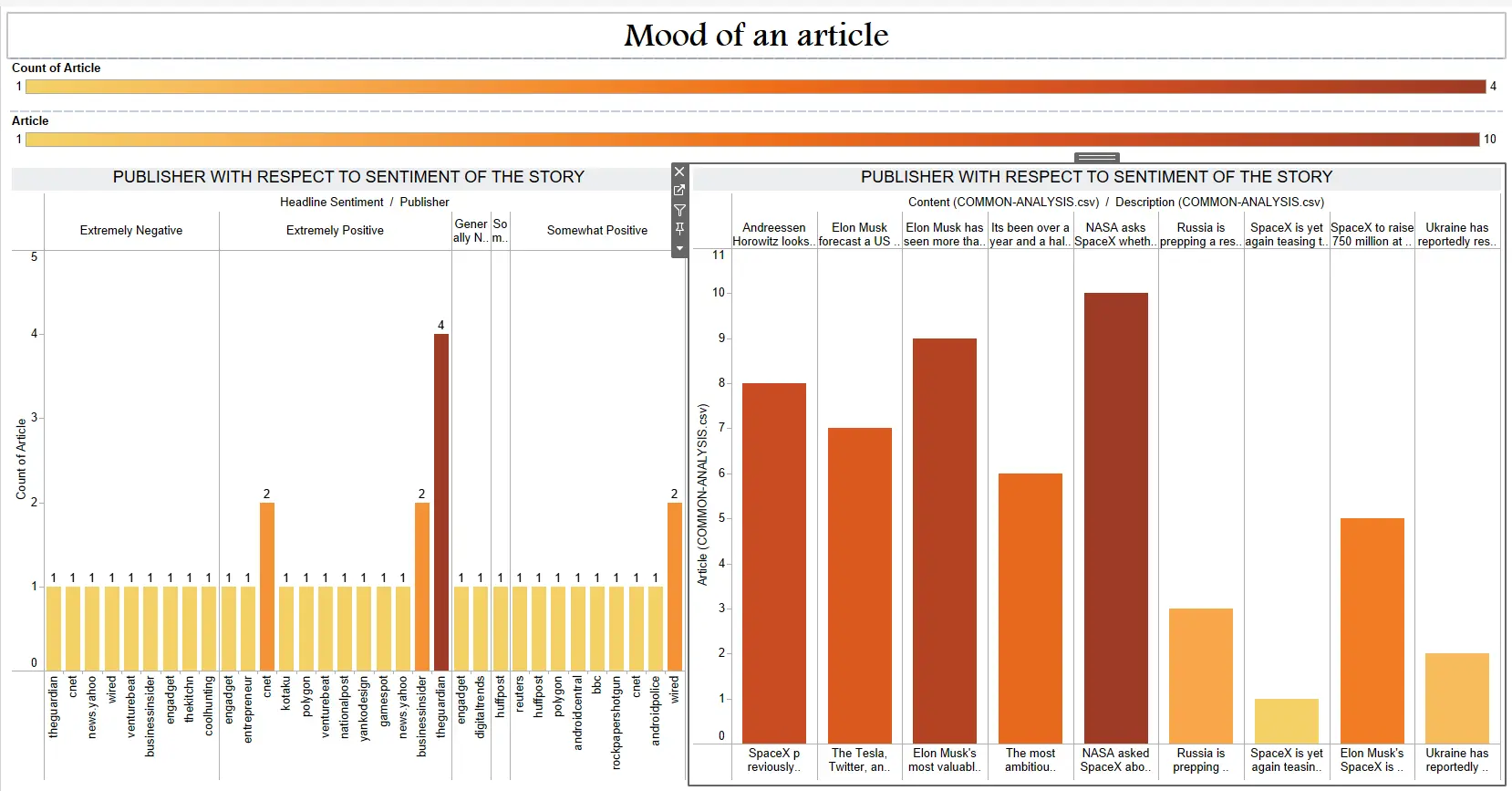
|
|---|
| Tableau Dashboard #4 |
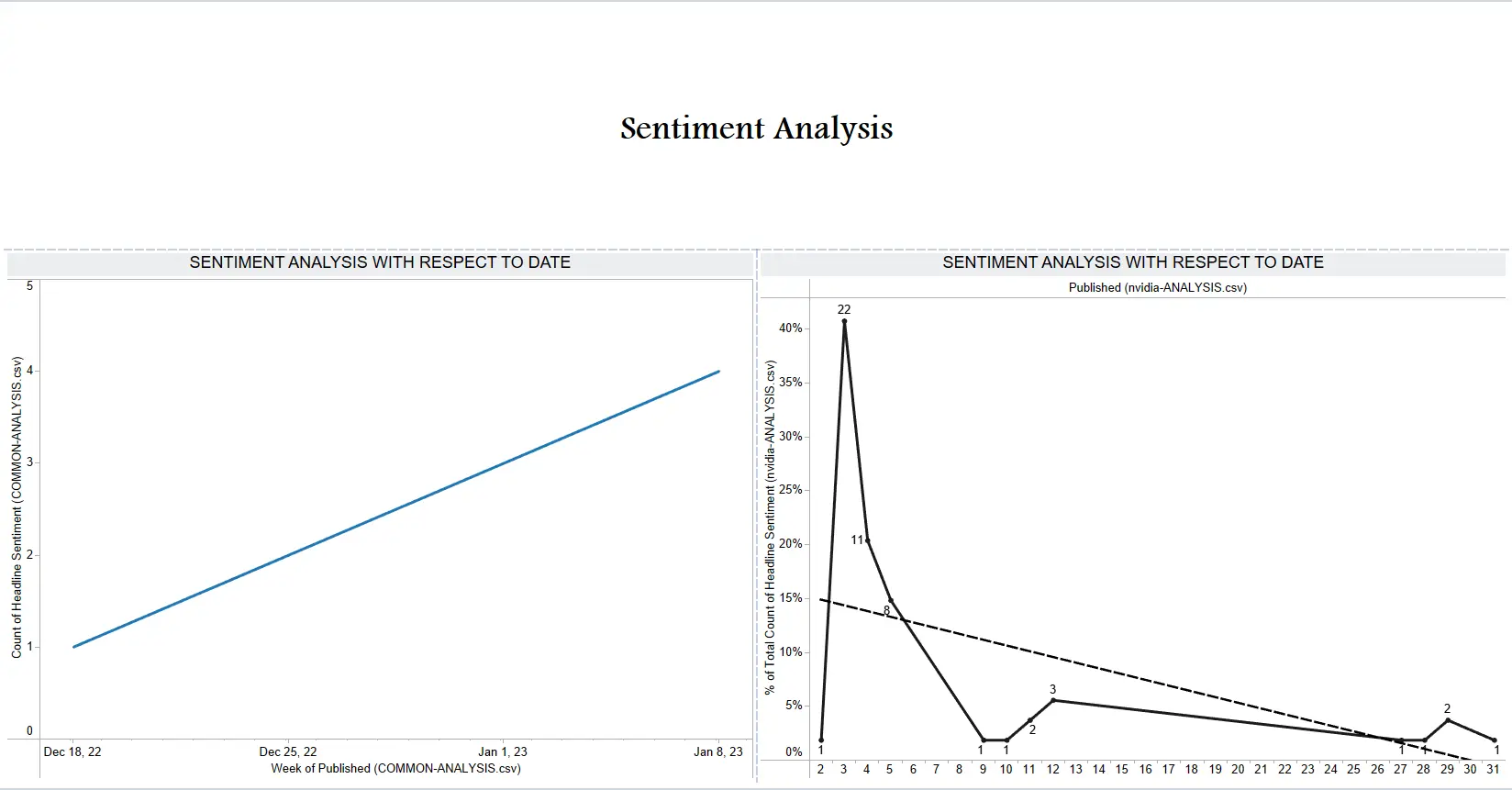
|
|---|
| Tableau Dashboard #5 |
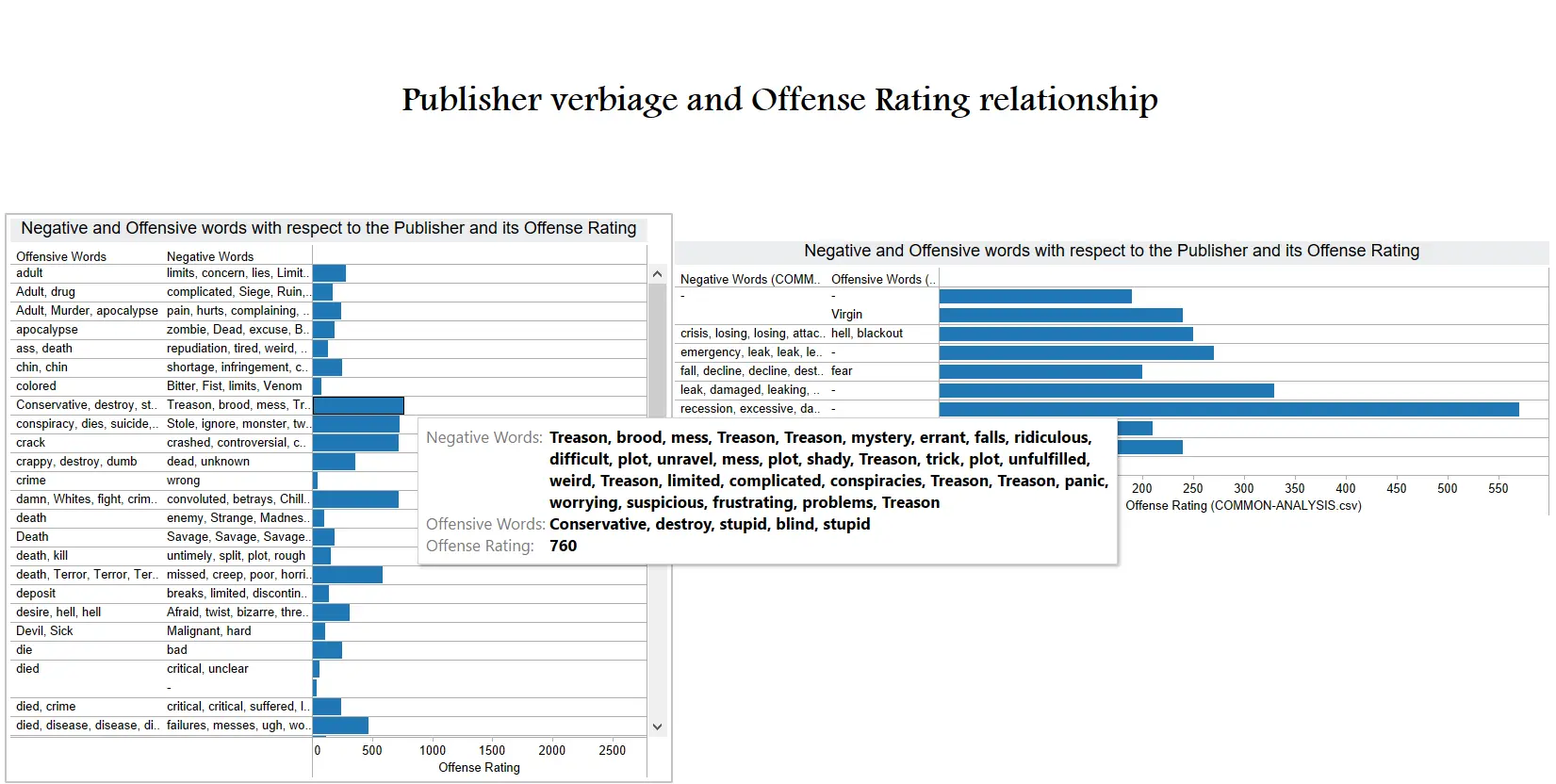
|
|---|
| Tableau Dashboard #6 |
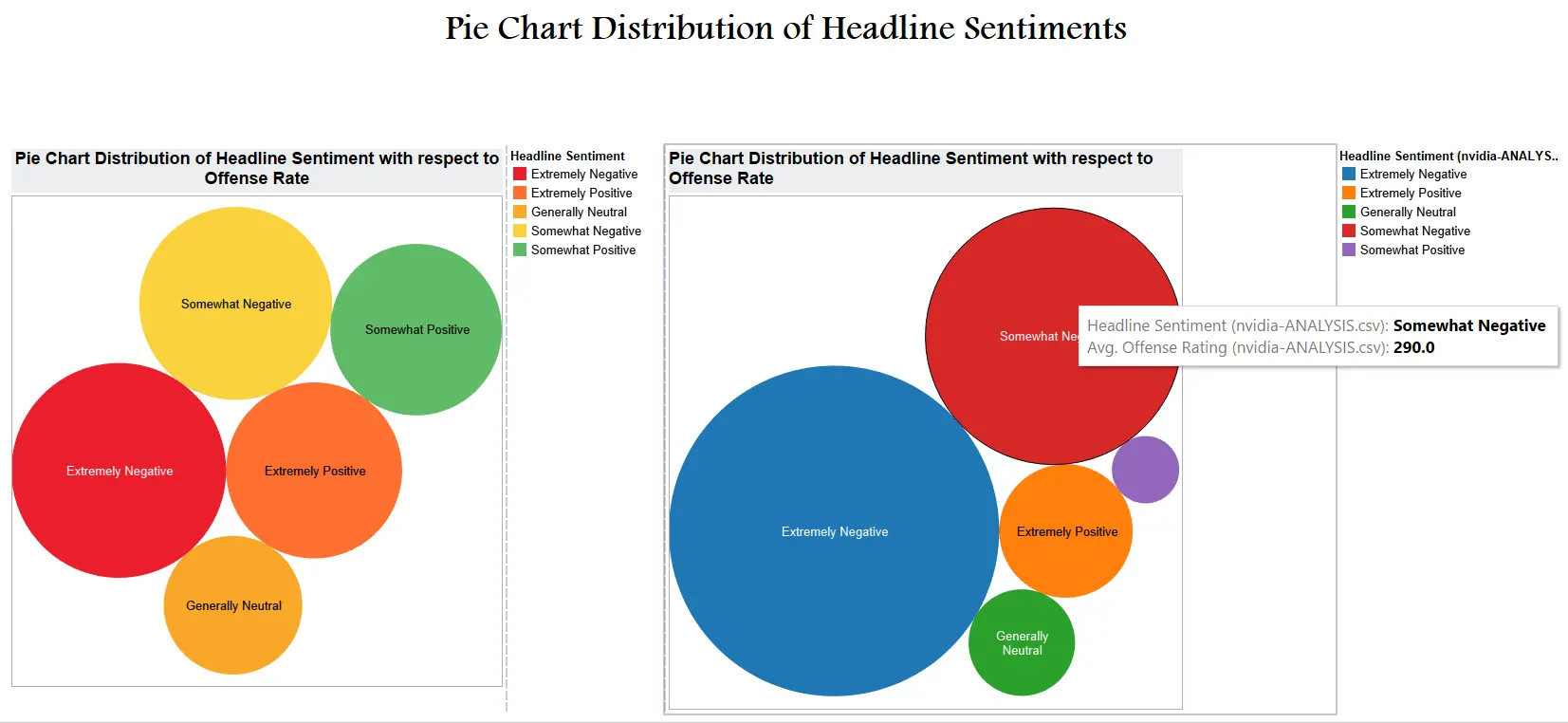
|
|---|
| Tableau Dashboard #7 |
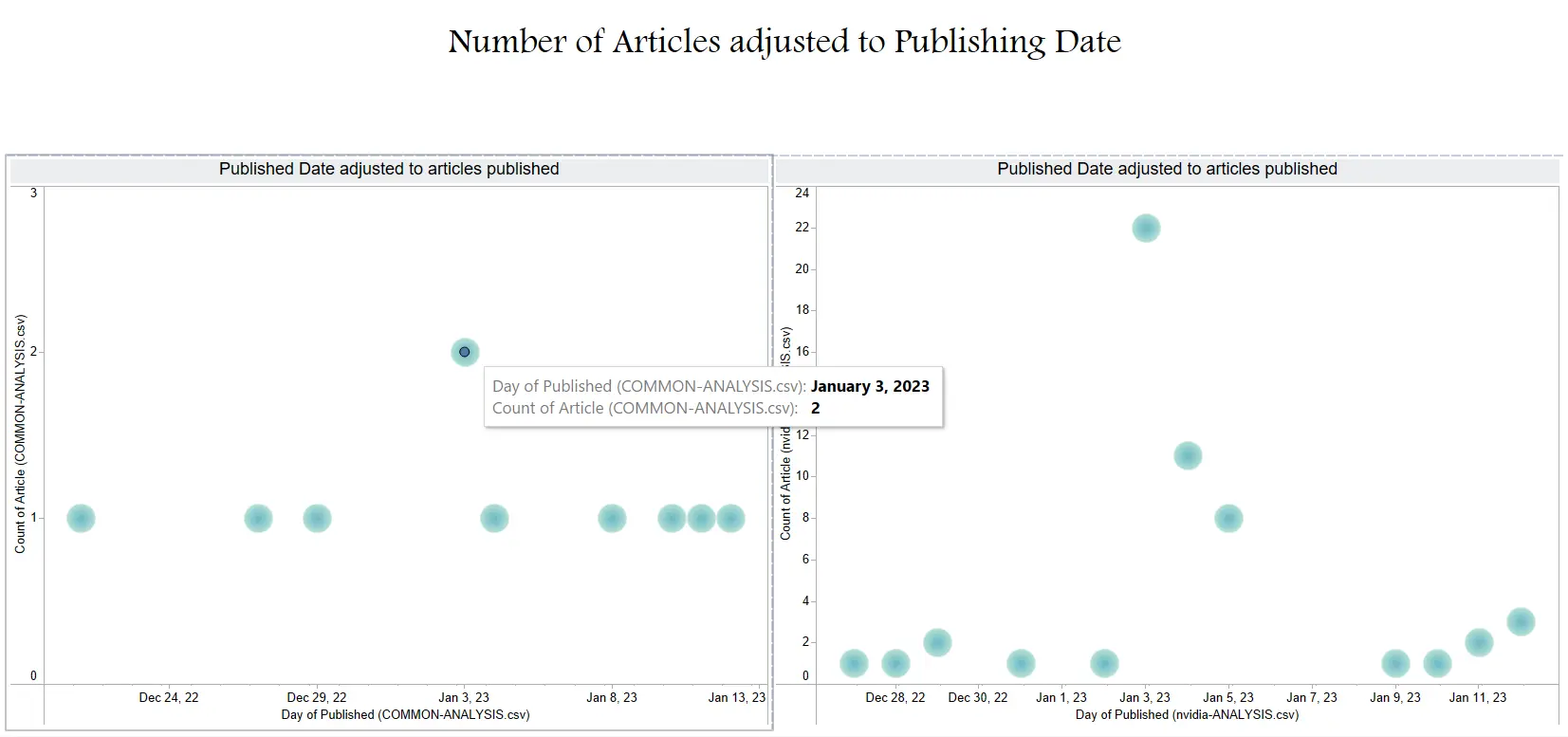
|
|---|
| Tableau Dashboard #8 |
Obstacles, Setbacks and Challenges faced
-
Cleaning up the article body and parsing proper text.
-
Extrapolating the context to base the negative score on.
-
Optimizing NLP processing and reducing the scraping time.
-
Tableau was a completely new tool for us, nonetheless we took a 2-hour crash course and got our hands dirty thanks to which we could quickly get ahead of the game and visualize our gathered data seamlessly.
-
Handling exceptions, 403, 404, Date Parsing, Tagging and taking care of API throttling.
-
Module 3 felt to be the most challenging since we had to add our own “risk-entity” NER support to the SpaCy “roBERTa” model while also not losing application efficiency.
Rewards
We worked around the clock in an organized manner and secured the first rank competing against 36 other teams (nearly 140+ participants). All the effort paid off at the end as we secured the first position after an exhaustive and interview-based project presentation with the panel of judges.
With the prestige and recognition we also received:-
- 50K Cash Prize
- Goodies for each team member
- Victory Certificate for each team member
- A “winner takes it all” trophy

|
|---|
| The taste of victory |